Kubernetes zuhause - Webanwendung nach außen verfügbar machen mit Ingress
Im vorherigen Beitrag habe ich podinfo als Anwendung installiert. Mit einer Port-Weiterleitung war die Anwendung dann im Browser aufrufbar. Für den regulären Betrieb war sie aber nicht erreichbar, da nur ein Service eingerichtet wurde und dieser den Traffic nur intern im Cluster verteilt. In diesem Beitrag will ich eine Ingress-Ressource anlegen, mit der die Anwendung auch außerhalb des Clusters erreichbar ist.
Andere Beiträge
Dieser Beitrag ist Teil einer Reihe von Blogposts. Ich betreibe zuhause einen Kubernetes-Cluster, in dem ich ein paar Anwendungen wie Nextcloud, Jellyfin oder Vaultwarden betreibe.
- Kubernetes zuhause mit Rancher Desktop und K3s - Einführung und Installation
- Praktische Tools - Die Arbeit mit Kubernetes etwas erleichtern
- GitOps mit Flux CI/CD - Kubernetes-Konfiguration im Git pflegen
- CI/CD-Deployment von Apps - CI/CD-Deployment von Apps
- Anwendung deployen mit Flux CI/CD und Helm
- Webanwendung nach außen verfügbar machen mit Ingress
Theorie im Hintergrund: Was ist eine Ingress-Ressource?
Mit Hilfe einer Ingress-Ressource wird Web-Traffic in den Cluster hinein geleitet, zum Beispiel an einen Service. Für gewöhnlich wird dazu ein Reverse-Proxy irgendeiner Art eingesetzt, beispielsweise nginx oder traefik. Für diese Proxies lassen sich verschiedene Regeln definieren, um HTTP-Requests von außen an bestimmte Pfade an dazu passende Endpunkte weiterzureichen.
Dabei geht es ausdrücklich um HTTP(S)-Traffic. Möchte man eine andere Anwendung von außen verfügbar machen, also einfach einen Port für z.B. TCP-Traffic irgendeiner Art öffnen, sind Ingress-Ressourcen nicht geeignet.
Ingress-Resource im Helm-Chart aktivieren
Das Anlegen von Ingress-Ressourcen ist etwas sehr gebräuchliches. Die meisten Helm-Charts sind deswegen auch bereits vorbereitet, das für die Anwendung geeignet zu machen. Im Fall des podinfo-Charts, das ich als Beispiel verwende, ist die Änderung denkbar einfach.
Zuerst wird die IP-Adresse benötigt, unter welcher der Kubernetes-Cluster erreichbar ist. Ich verwende Rancher Desktop für die lokale Entwicklung, also kann ich die hier notwendige IP-Adresse nachsehen:
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
lima-rancher-desktop Ready control-plane,master 31d v1.25.4+k3s1 192.168.0.126 <none> Alpine Linux v3.16 5.15.78-0-virt containerd://1.6.8
Die gesuchte IP-Adresse ist hier die 192.168.0.126 - zu finden unter Internal IP. Je nach Setup kann auch unter External IP ein Wert stehen. Diese Zuoordnung hängt von der jeweiligen Implementierung der verwendeten Kubernetes-Distribution ab.
In der apps/podinfo/helmrelease-podinfo.yaml bearbeite ich das HelmRelease und füge bei den values die Konfiguration für die Ingress-Ressource hinzu:
# […]
releaseName: podinfo
values:
replicaCount: 1
ingress:
enabled: true
hosts:
- host: "podinfo.192.168.0.126.nip.io"
Damit wir die Anwendung unter http://podinfo.192.168.0.126.nip.io verfügbar. Nachdem ich nur lokal entwickle und keinerlei externes DNS eingerichtet habe, nutze ich den praktischen nip.io-Dienst. Hier wird die DNS-Anfrage nach der Domain einfach mit der IP in der URL beantwortet.
Nach einem Commit und Push in mein Git-Repository wird Flux automatisch das HelmRelease im Hintergrund aktualisieren und der Helm-Controller wird die notwendige Ingress-Ressource anlegen. Sind diese Vorgänge abgeschlossen, kann ich mit dem Browser http://podinfo.192.168.0.126.nip.io aufrufen und sehe die Oberfläche von podinfo.
Was passiert im Cluster?
Das war jetzt ein sehr bequemes Setup, mit viel Abstraktion. Das ist die Stärke von Kubernetes - wie genau meine gewünschte Konfiguration implementiert wird, kann mir häufig egal sein. Als Anwendungsentwickler etwa möchte ich nur konfigurieren, dass die Anwendung eine bestimmte URL hat. Wie intern die Zuordnung zu den passenden Containern stattfindet, muss mich nicht weiter kümmern.
Nun interessiert mich als Admin aber durchaus, was hier passiert - und wie. Darum geht es im Folgenden.
Wer beantwortet HTTP Requests von außen?
Im Beispiel habe ich einfach die IP-Adresse der VM, die Rancher Desktop in meinem lokalen Netzwerk betreibt, hergenommen und dort Port 80 aufgerufen. An diesem Port ist traefik ran gegangen, der standardmäßig bei Rancher Desktop eingesetzte Reserve Proxy. Dieser hat die Anfrage dann an podinfo weiter geleitet. Wieso ist aber ausgerechnet traefik auf dieser IP und diesem Port erreichbar?
Für gewöhnlich kommen bei Kubernetes für diese Zwecke Load Balancer zum Einsatz. Ihre Aufgabe ist es, Requests von extern anzunehmen und in den Cluster zu leiten. Dafür gibt es verschiedene Implementierungen und Kubernetes kommt ohne Standard-Implementierung.
In Cloud-Umgebungen wie bei AWS oder in der Google Cloud werden spezifische Load-Balancer verwendet, die vom jeweiligen Cloud-Provider bereitgestellt werden. Diese kümmern sich um die Verteilung des Traffics auf die am Cluster beteiligten Nodes. Auf Seiten des Clusters geht auch wieder auf einem dem Load Balancer bekannten Port für gewöhnlich ein Kubernetes-Service ran, der den Traffic dann nochmal intern an die richtigen Pods verteilt.
Ohne Cloud-Umgebung muss man sich selbst um diesen Teil kümmern. Bei Rancher Desktop kommt unter der Haube k3s als Kubernetes-Distribution zum Einsatz. Dort wird ServiceLB genutzt. Auf jeder am Cluster beteiligten Node läuft eine Instanz des svclb-Pods. Diese Pods haben in ihrer Definition unter anderem eine HostPort-Direktive stehen. Mit Hilfe von iptables wird Traffic, der auf Port 80 der Node ankommt, direkt an diesen Pod weitergeleitet. Weil die Pods in einem DaemonSet gestartet werden, läuft auf jeder Node ein solcher Pod und kann Traffic entgegennehmen. Als LoadBalancer gibt ServiceLB dann den Traffic weiter an den Service im Cluster, der den traefik-Reverse-Proxy betreibt.
Das sind überraschend viele Schritte der Indirektion, behandelt allerdings auch ein paar Probleme, die man in Clustern haben kann:
- Port
80und443sind privilegiert und können nicht einfach von Anwendungen in Beschlag genommen werden. Kubernetes erlaubt etwa NodePort-Services nur an Ports ab 30000 zu binden. - Port
80und443sind beliebt, andererseits auf einer VM aber auch nur jeweils einmal belegbar. - Der Traffic muss zwischen den am Cluster beteiligten Nodes verteilt werden. Die dazu verwendbaren IP-Adressen können sich jederzeit ändern.
- In Cloud-Umgebungen können die Load Balancer außerhalb des Clusters betrieben werden und benötigen daher keine Ressourcen des Clusters. Es ist darüber hinaus auch möglich, entsprechend resiliente Setups wie Elastic Load Balancer von AWS zu verwenden, ehe Traffic in den Cluster geht
Im Fall von Rancher Desktop und k3s sind natürlich nicht alle dieser Vorteile vorhanden. Das ist für lokale Entwicklung vollkommen in Ordnung. Immerhin wird noch automatisch abgenommen, dass pro VM ein Pod gestartet werden muss, der den Traffic auf Port 80 und 443 entgegennimmt und durch den Cluster leitet.
Wohin geht der Traffic innerhalb des Clusters?
Der Traffic ist mittlerweile vom Load Balancer an den Service für traefik weitergegeben worden. Im Cluster können damit ein oder mehrere Pods mit dem Reserve-Proxy angesprochen werden. Wie dann der HTTP-Traffic weitergegeben wird, oder ob noch Authentifizierung gemacht wird, TLS terminiert wird oder nach welchen Regeln ausgesucht wird, wohin genau der Traffic geht, wird in Ingress-Ressourcen definiert. In meinem Beispiel hat Helm so eine einfach angelegt. Diese anzusehen ist glücklicherweise einfach:
$ kubectl get -o yaml -n podinfo ingress podinfo
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
namespace: podinfo
spec:
ingressClassName: traefik
rules:
- host: podinfo.192.168.0.126.nip.io
http:
paths:
- backend:
service:
name: podinfo
port:
number: 9898
path: /
pathType: ImplementationSpecific
status:
loadBalancer:
ingress:
- ip: 192.168.0.126
(Ausgabe gekürzt)
Das YAML für diese Ressource musste ich praktischerweise nicht selbst schreiben. Es hilft aber, es zu verstehen:
- Im Namespace
podinfogibt es Ressource vom TypIngressmit dem Namenpodinfo. - Verschiedene Ingress-Klassen können definiert werden. Hier ist die
ingressClassNameeinfachtraefik, also wird sich der Ingress Controller fürtraefikum die Umsetzung dieser Konfiguration kümmern. - Es gibt einfaches Traffic-Routing in den
rules. Für den angegebenenhostwird der Traffic für denpath/an denservicemit Namenpodinfoauf Port9898weitergeleitet, auf dem der Service auf HTTP-Requests wartet. - Die Details, wie genau der Load Balancer Traffic hin schickt, werden auch erfasst.
Nun weiß ich also:
- Traffic kam am Load Balancer an, der hat ihn an traefik weitergeleitet, der auf Port
80der VM hört. - Dieser hat seine Konfiguration aus einer Ingress-Ressource bekommen.
- traefik leitet den Traffic an den Service
podinfoweiter
Was der Service macht, lässt sich ebenfalls herausfinden:
$ kubectl describe -n podinfo service podinfo
Name: podinfo
Namespace: podinfo
Selector: app.kubernetes.io/name=podinfo
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.43.244.205
IPs: 10.43.244.205
Port: http 9898/TCP
TargetPort: http/TCP
Endpoints: 10.42.0.37:9898
(Ausgabe gekürzt)
Hier lässt sich verstehen:
- Der Service heißt
podinfound lebt imNamespacepodinfo. - Er spricht alle Pods an, die als Label gesetzt haben:
app.kubernetes.io/name=podinfo. - Der Service ist vom Typ ClusterIP, das heißt er ist auf einer im Cluster erreichbaren RFC1918-IP erreichbar, auf
Port 9898/TCP. - Traffic an
Port9898/TCPwird an den in der Pod-Definitionhttpbezeichneten Port weitergeleitet. Bemerkenswerterweise ist das im Fall vonpodinfonicht80sondern auch9898. Namen und Nummern sind hier frei wählbar. - Zu den Endpunkten gehört hier nur eine IP (weil nur ein Pod läuft):
10.42.0.37:9898.
Nun ist die Kette komplett:
- Traffic kam am Load Balancer an, der hat ihn an traefik weitergeleitet, der auf Port
80der VM hört. - Dieser hat seine Konfiguration aus einer Ingress-Ressource bekommen.
- traefik leitet den Traffic an den Service
podinfoweiter - Der Service nimmt Traffic an Port
9898/tcpentgegen und sammelt alle Pods, die mit dem Selector gesucht werden können. Der Traffic wird auf die so gefundenen Pods auf den passenden Ports geleitet.
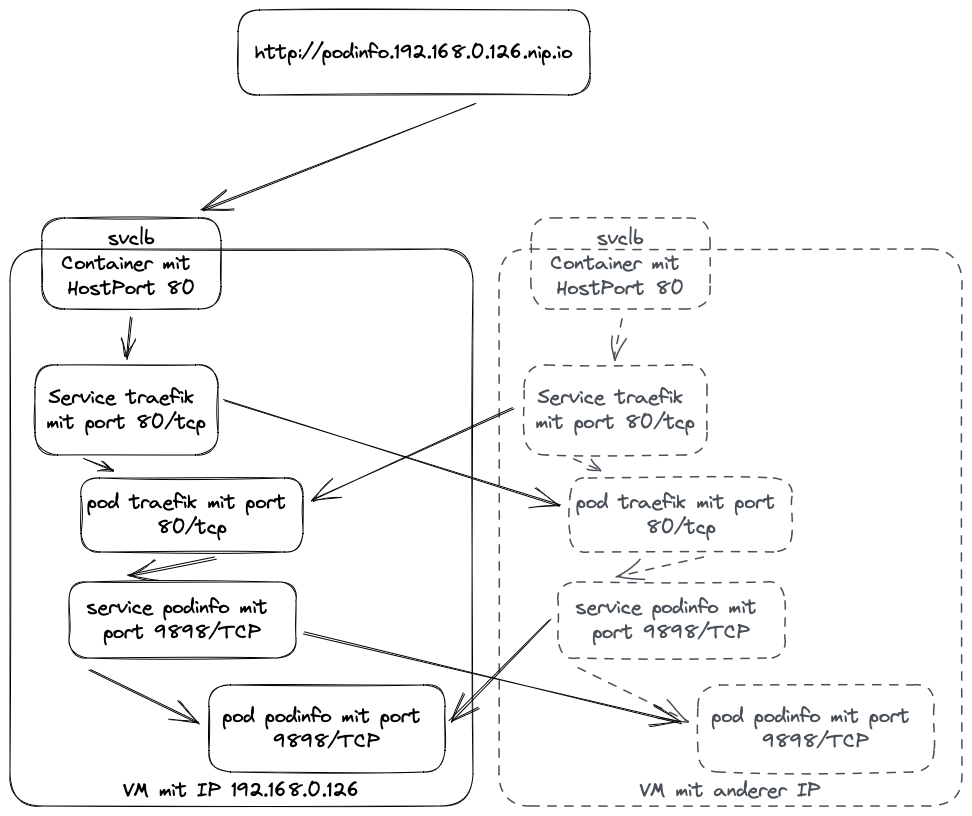
Größere Setups
Wie im Schaubild schon erkennbar ist, skaliert diese Lösung nicht gut ins unendliche. Ich rufe aktuell die Anwendung auf der IP meiner einzigen Kubernetes-Node auf. Dort geht dann der Load Balancer auf Port 80 ran und erst im Cluster werden dann Anfragen überhaupt auf andere potentiell vorhandene Nodes verteilt. Das ist für kleine Setups vollkommen in Ordnung. In größeren Setups kann der Load Balancer eine von der IP natürlich unabhängige URL haben und die am Cluster teilnehmenden Nodes kennen und anhand seiner Konfiguration den Traffic an die verschiedenen Nodes verteilen. In Cloud-Umgebungen können das, wie gesagt, spezifische Load Balancer-Lösungen der Cloud-Provider erfüllen. Für lokale Installationen gibt es hier etwa Metal LB. Dazu in einem späteren Beitrag mehr.